
- I’m Dongjie Cheng (程东杰), a PhD student in the Department of Computing at The Hong Kong Polytechnic University (PolyU), advised by Prof. Wenjie Li and Prof. Yongqi Li. I received my B.Eng. in Artificial Intelligence from Sichuan University.
- My research interests lie in the Multimodal Large Language Models and Unified Multimodal Models. I also always maintain an open mind and am willing to learn new things. You can find my main research interests on

🔥 News
- 2025.03: 🎉🎉 I’ll be joining PolyU as a PhD student in Fall 2025—see you in 🇭🇰!
- 2024.10: 🎉🎉 Thanks to all collaborators and mentors, my Google Scholar citations have now reached 100.
- 2024.09: 🎉🎉 CSR was accepted by NeurIPS 2024
- 2024.08: 🎉🎉 TV-SAM was accepted by Big Data Mining and Analytics (JCR Q1, 中科院1区, IF=7.7)
- 2024.07: 🎉🎉 The short version of CSR was presented in ICML 2024 FM-Wild Workshop
📝 Research Publication
- Calibrated self-rewarding vision language models
Co-First Author, Accepted, NeurIPS-2024
(The short version is presented in ICML 2024 FM-Wild Workshop)
- TV-SAM: Increasing Zero-Shot Segmentation Performance on Multimodal Medical Images Using GPT-4 Generated Descriptive Prompts Without Human Annotation
Co-First Author, Accepted, Big Data Mining and Analytics (JCR Q1, 中科院1区TOP, IF=7.7)
- SAM on Medical Images: A Comprehensive Study on Three Prompt Modes
Co-First Author, Cited by: 540
- Evaluating Hallucination in Text-to-Image Diffusion Models with Scene-Graph based Question-Answering Agent
Co-First Author
📖 Education
Ph.D. in Computing, 2025-Now, The Hong Kong Polytechnic University (PolyU)

B.S. in Artificial Intelligence, 2021-2025, Sichuan University, GPA (Compulsory): 3.9/4, 91.51/100

🎖 Honors & Awards
- National Scholarship (1/48 that year)2023.11
- National Third Prize, “China Software Cup - Finals”2023.08
- Second Prize, “RoboMaster - North Region Competition”2023.06
- Second Prize, “National College Mathematics Competition”2021.12
💻 Experience
PolyU
- PhD student of Prof.Wenjie Li ’s Lab
- September, 2025 - Present
- Supervisor: Prof.Wenjie Li, Prof.Yongqi Li
WEST CHINA HOSPITAL – BIG DATA CENTER
- Research Assitant of Prof.Kang Li ’s Lab
- February, 2023 - August 2024
- Supervisor: Prof.Kang Li, Prof.Qicheng Lao
UNC-CHAPEL HILL
- Remote Intern of Prof.Huaxiu Yao ’s Lab
- March, 2024 - September, 2024
- Supervisor: Prof.Huaxiu Yao
🧩 Projects
🎙 VLM self-rewarding project
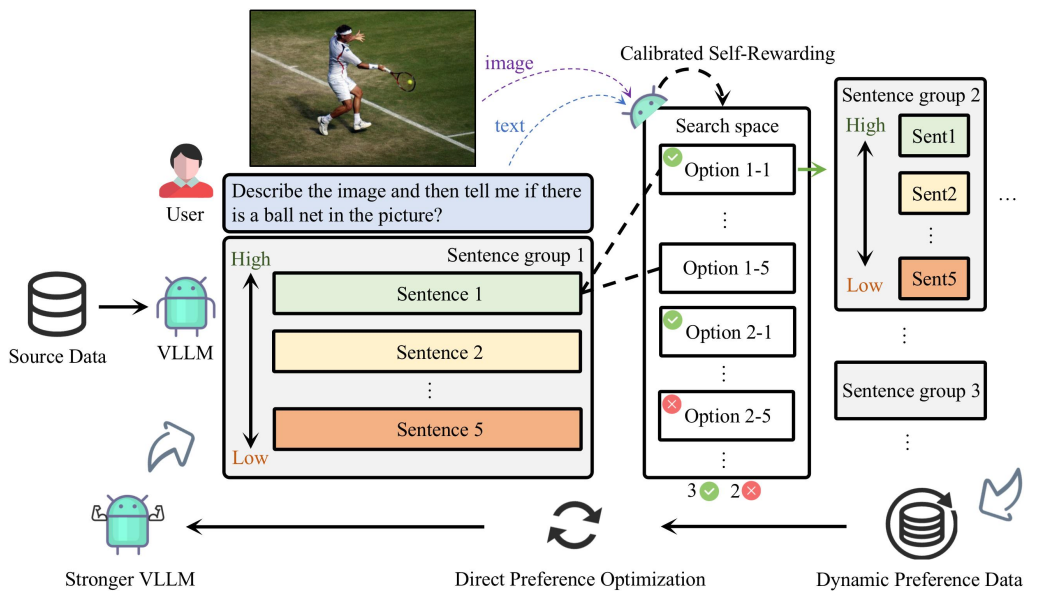
📝 Calibrated Self-Rewarding Vision Language Models
🔗 Project
- Our work addresses misalignment challenges in LVLMs by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning. In the reward modeling, we employ a step-wise strategy and incorporate visual constraints into the self-rewarding process to place greater emphasis on visual input. Empirical results demonstrate that CSR enhances performance and reduces hallucinations across ten benchmarks and tasks, achieving substantial improvements over existing methods by 7.62%. Our empirical results are further supported by rigorous theoretical analysis, under mild assumptions, verifying the effectiveness of introducing visual constraints into the self-rewarding paradigm.
- I was responsible for the specific implementation and optimization of the CSR method, as well as core tasks such as DPO training and SFT training for VLM.
👨⚕️ SAM project
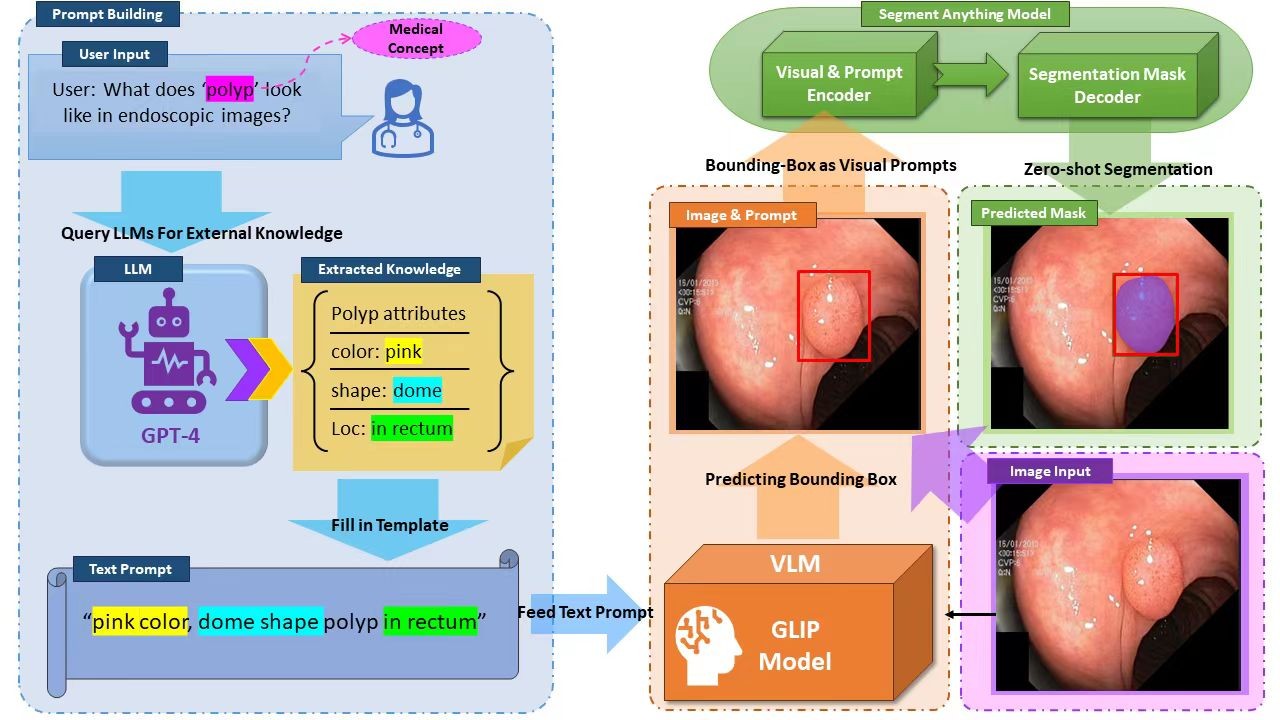
📝 SAM on Medical Images: A Comprehensive Study on Three Prompt Modes.
🔗 Project
- In the SAM project, We proposed using large models to generate descriptions for segmentation targets, feeding theses descriptions to the detection model to produce bounding boxes for SAM, thereby achieving zero-shot segmentation.
- I was responsible for conceiving and implementing specific experiments. Firstly, I completed the evaluation of the SAM model on multiple modalities medical datasets. Then I verified the effectiveness of the improvement method driven by LLM (Large Language Models).
- The results show that the improved method performs well under zero-shot conditions, outperforming the Grounded-SAM baseline on most datasets. The project ultimately resulted in two papers, of which I am a co-first author.
📏 T2i-Eval project
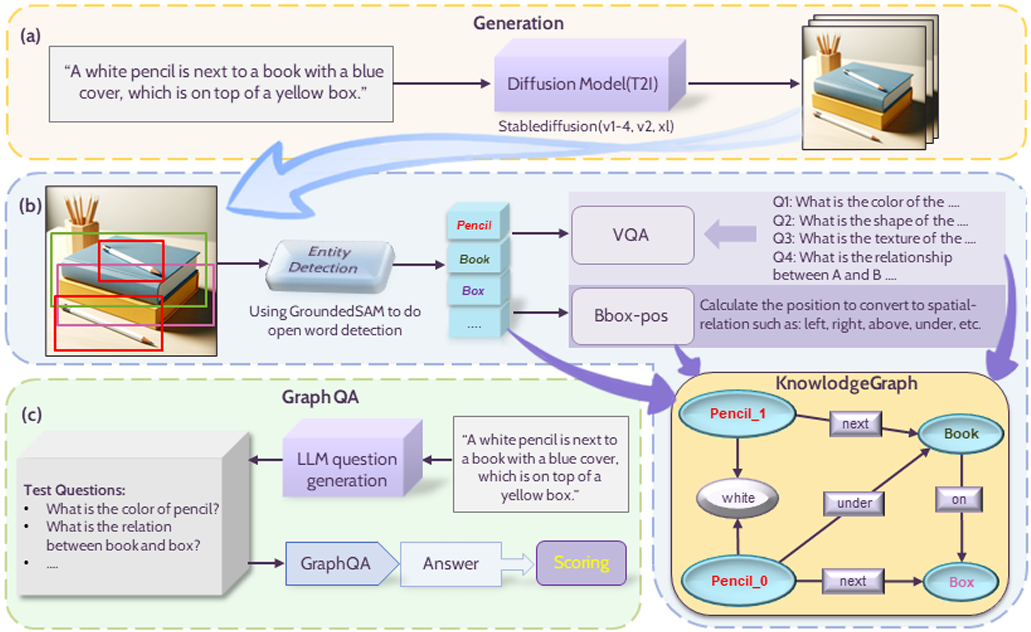
- In the T2i-Eval project, we proposed a method combining Scene Graph and Graph QA to score the quality of generated images, conducting a comprehensive evaluation of images from perspectives such as object omission, attribute inaccuracies, relational errors, and hallucinations.
- I was responsible for generating evaluation dataset images, the specific design and experimentation of the Scene Graph part, achieving the construction of Scene Graphs through the use of GroundingDINO+BLIP VQA.
- We constructed a human-evaluated dataset containing 12,000 images from 1,000 prompts and validated the effectiveness of our method. Compared with human evaluations, our Pearson and Kendall correlation coefficients surpassed those of T2ICompbench(Neurips 2023). This project ultimately resulted in one paper, for which I am a co-first author.
🔭 Interests
- 🎹 Piano (Amateur Level 10, Issued by Shanghai Conservatory of Music)
- ✏️ Sketch & Quick Sketch (Amateur Level 4&6)
- 🌄 Hiking
- ⚽ Football (I’m a big fan of BVB.)

- 🕹️ Games (CS2, Valorant, RainbowSix…)