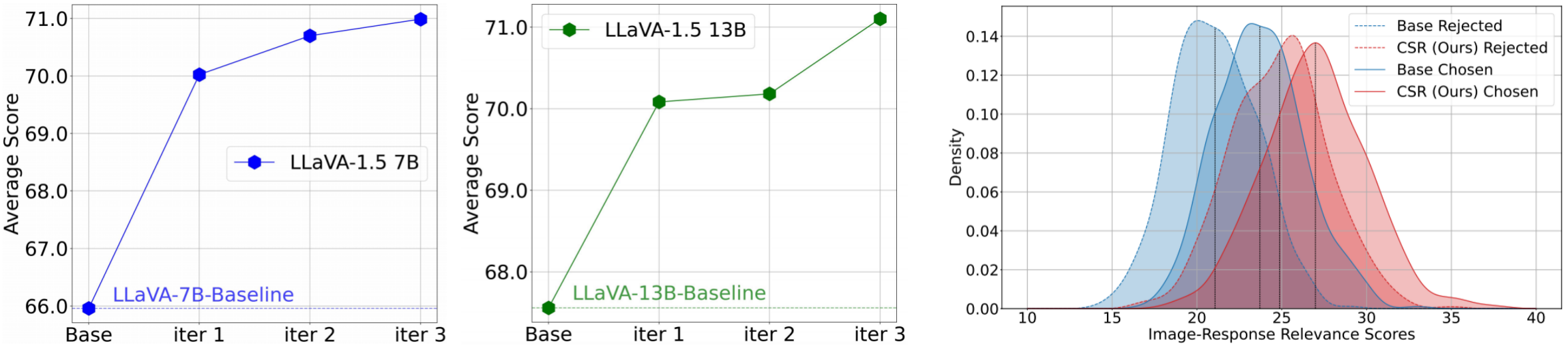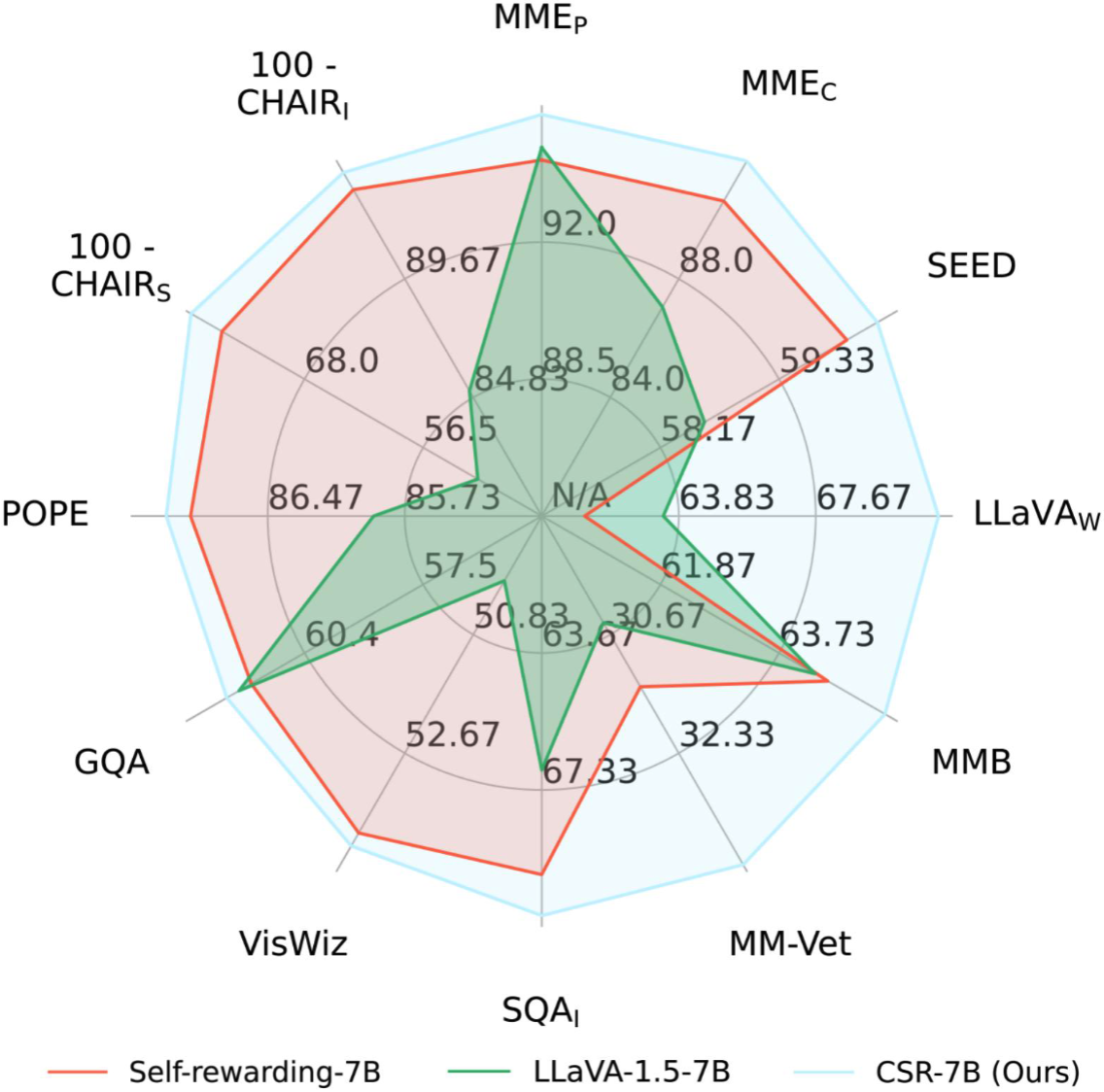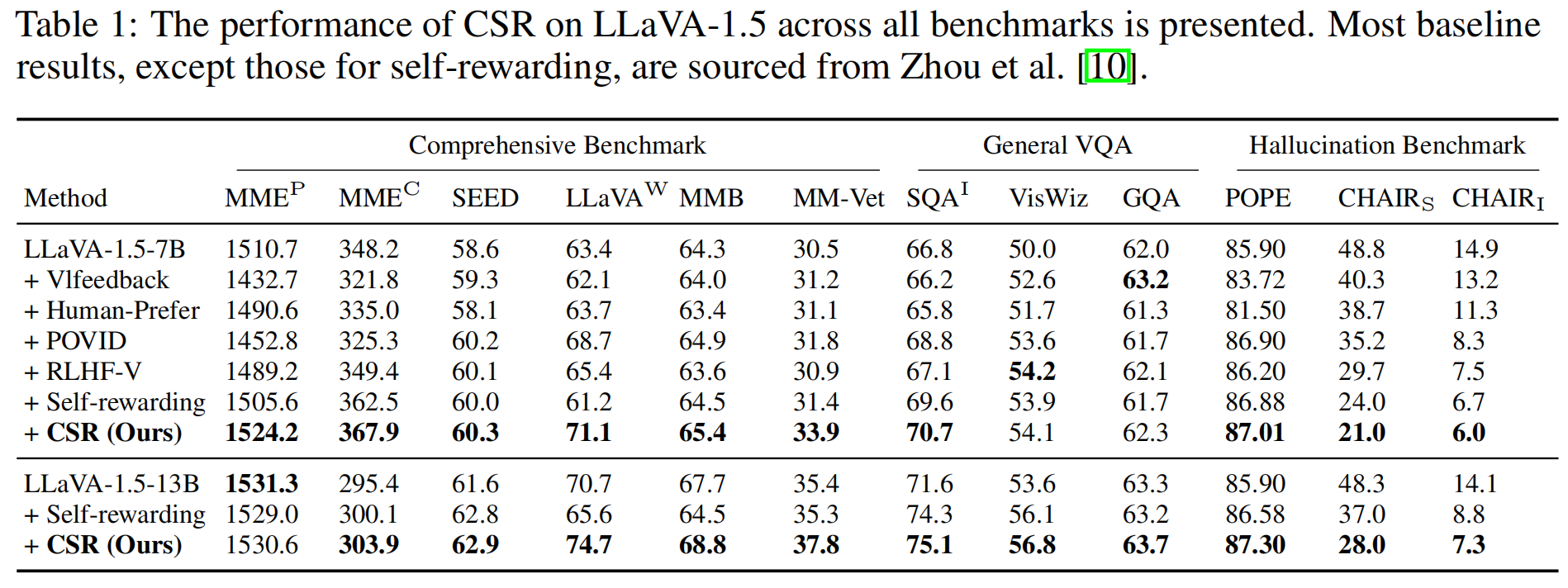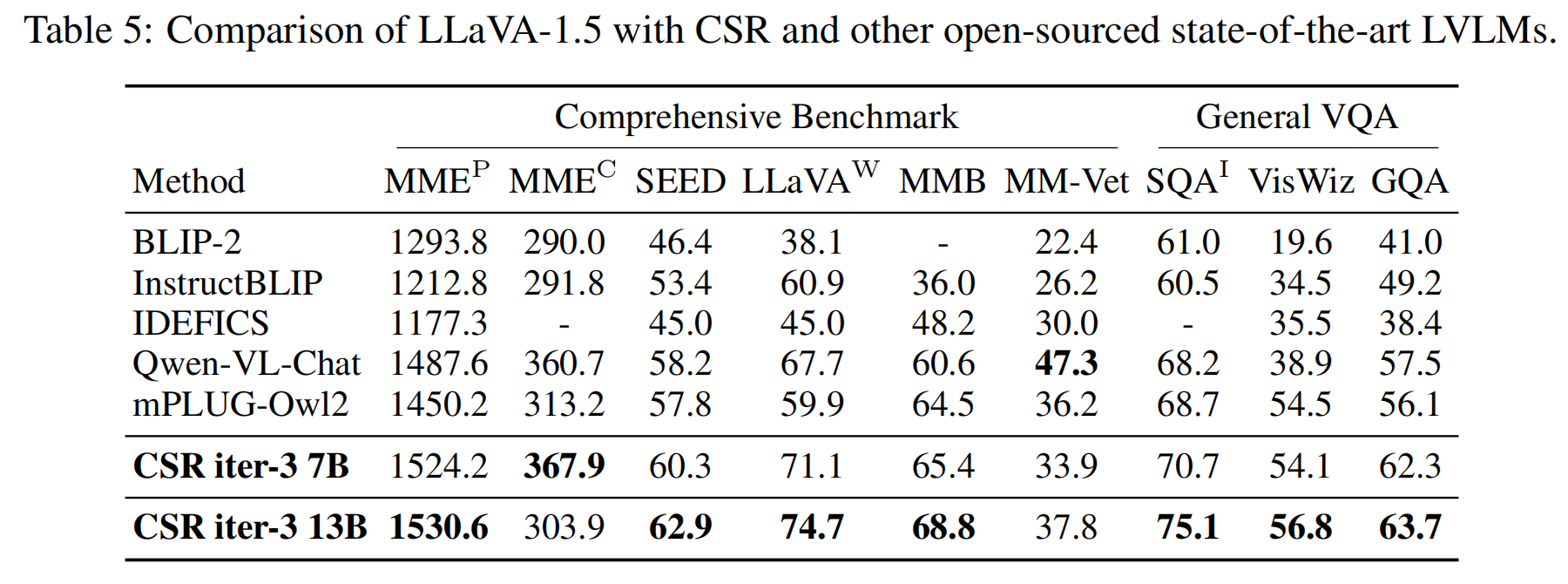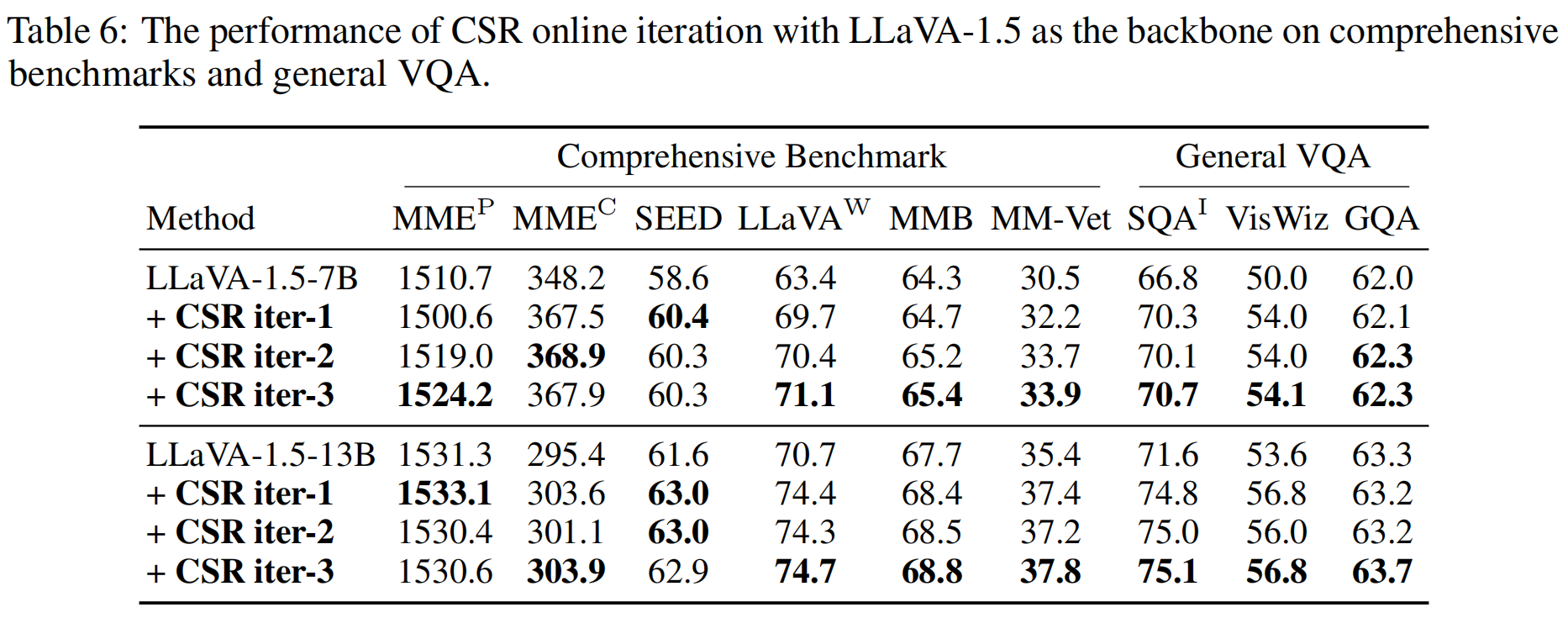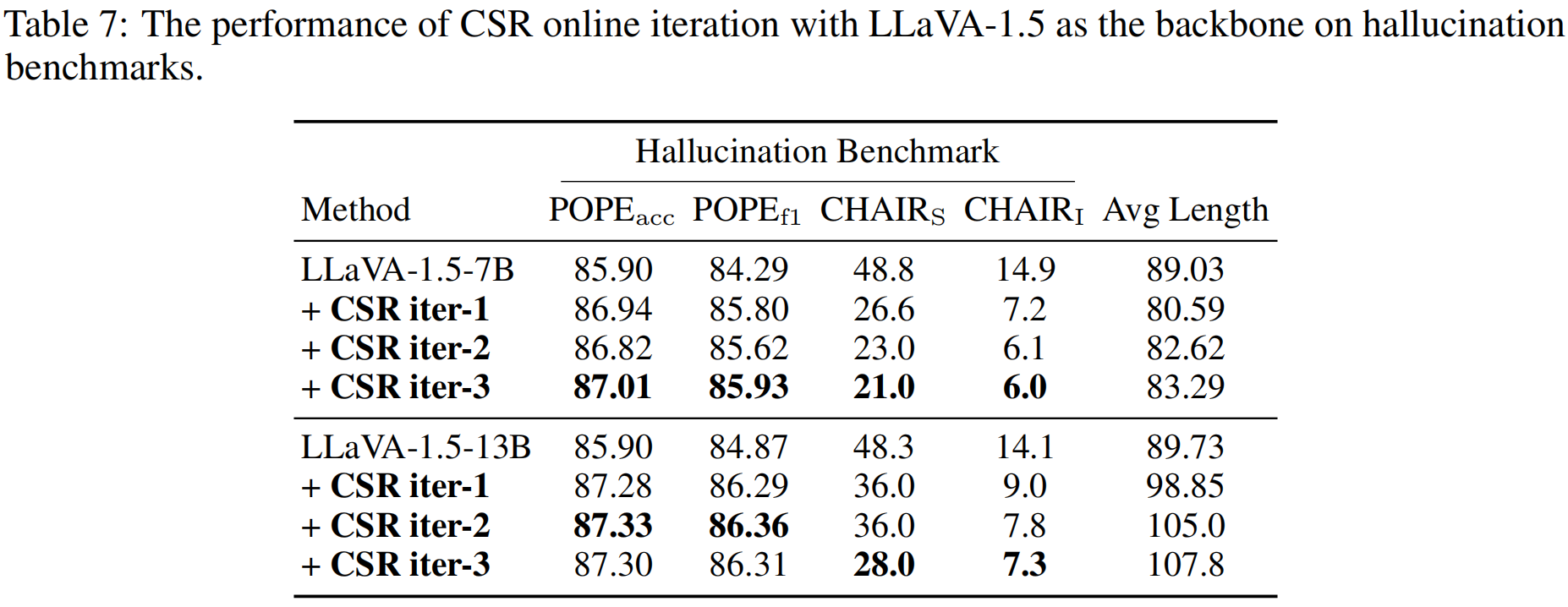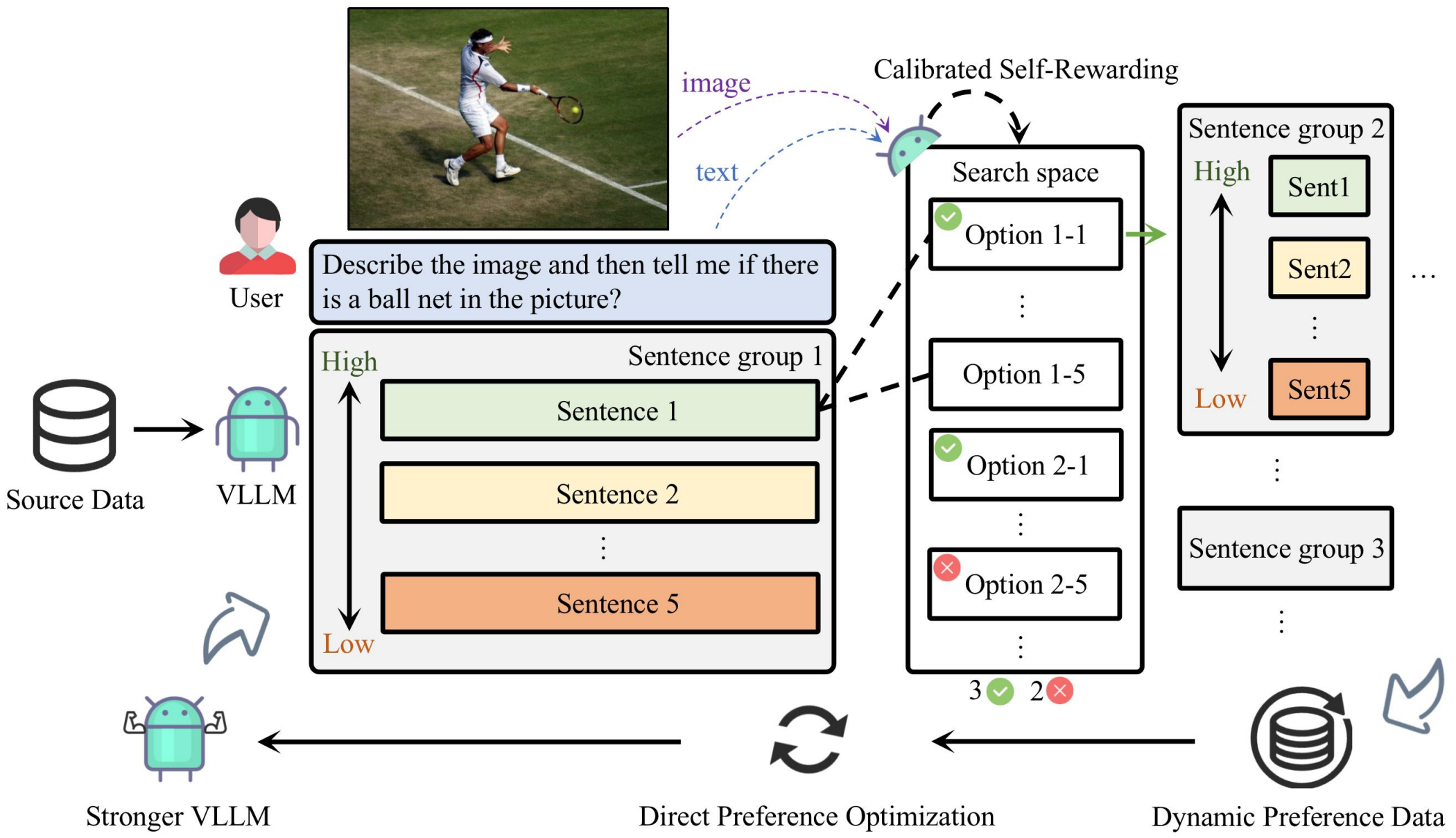
The CSR framework operates an iterative process of preference data generation and learning. During preference data generation, CSR utilizes a sentence-level beam search approach to construct responses sentence by sentence, assigning a reward to each sentence. This reward, initially generated by the model itself, is then calibrated using image-relevance information. Preferences are determined based on the cumulative reward for each response. In each iteration, CSR generates new preference data and performs preference learning based on this data, continuously enhancing the model's performance.